Skupiny záznamů v číselnících
Některé z číselníků podporují práci se skupinami záznamů. Tj. umožňují si rozdělit všechny záznamy v číselníku do definovaných skupin a pracovat pak pouze s vybranou skupinou. Skupinování se provádí tak, že se provede SQL dotaz do databáze a provede se znovunačtení číselníku, a to jen jeho části (podle získaných interních identifikátorů (ID) vyhovujících záznamů). Podrobněji viz dále. Tj. umožňuje načíst do paměti klienta jen podmnožinu záznamů z číselníku a tím efektivněji pracovat s číselníkem obsahujícím velké množství záznamů.
Příklad 1: Uživatel potřebuje do Adresáře načíst větší počet potenciálních klientů (např. z nějaké koupené databáze firem). Aby ale ohromný nárůst záznamů v číselníku nekomplikoval práci ostatním, kteří pracují jen s aktivními firmami, potřebuje je rozdělit do skupin, např. "jen aktivní" a "potenciální", přičemž do paměti se načte seznam potenciálních jen na žádost uživatele. Pak lze vytvořit skupinu s nastavením podmínek tak, aby vracela jen požadované záznamy. Pokud toho nelze dosáhnout pomocí existujících podmínek dodávaných výrobcem, lze využít uživatelsky definovatelné položky.
Příklad 2: Číselník šarží – zde lze s výhodou použít skupinu s podmínkou "pouze nenulové šarže / sériová čísla". Pak lze načíst jen stále aktuální šarže/sériová čísla.
Příklad 3: Lze využít i pro rozdělení práce – jedna osoba sestaví pracovní (dočasnou) skupinu, předá informaci druhé osobě, která záznamy ze skupiny zpracuje a postupně je vyřazuje.
Použití skupin v nevhodném případě může být kontraproduktivní a může naopak způsobit zpomalení v odezvě systému. Někde je lépe použít místo skupin záznamů filtrování a naopak. Viz Skupiny versus filtrování či jiné omezení číselníků.
Jedná se o jednu možností omezení záznamů zobrazených v číselníku.
Dále je uvedeno:
Jak bylo objasněno v kap.
Nicméně v některých situacích (zejména u číselníků, kde se předpokládá velký počet záznamů) je užitečné moci si i v číselníku nechat načíst z databáze do paměti jen jeho část, tj. ty záznamy, které splňují zadané podmínky. Jedná se o:
- Adresář firem
- Adresář osob
- Šarže a sériová čísla
- Zakázky
- Obchodní případy
- Projekty
- Obrázky
- Měsíční údaje pracovního poměru
Skupina je definována pouze na základě DynSQL omezení. Výhodou tohoto řešení je možnost zařazování záznamů do více skupin současně, což je v praxi potřeba. Uživatel tedy ve vybraných číselnících může definovat skupiny (definovat podmínky, které musí záznam splňovat, aby byl načten z databáze, pokud je daná skupina vybrána) a přepínat mezi nimi. Zde je možno použít všechny omezovací podmínky dostupné v dané agendě pro výběry dat z databáze včetně uživatelsky definovatelných položek (mají-li v definici nastaveno Používat pro omezení výběrů dat). Uživatel si tak může vytvářet i poměrně složité varianty skupinování.
Hodnoty do uživatelsky definovatelných položek doplněných do agend později lze dozadat i hromadně, viz Možnosti hromadných oprav.
Skupinování v číselnících pracuje na tom principu, že podle definice vybrané skupiny se provede příslušný dotaz do databáze a podle výsledků, které vrátí, se načtou do paměti počítače jen ty záznamy z číselníku, které provedenému dotazu vyhovují.
Skupiny záznamů jsou principiálně totéž, jako omezování v dokladových agendách a tudíž použitím skupiny u číselníku s mnoha záznamy se práce s ním urychlí, obdobně jako je tomu při omezování dokladových agend.
Jelikož se u číselníků podporujících skupinování načítají záznamy pomocí DynSQL dotazu (nikoli akcí jako je tomu u ostatních číselníků), uplatní se při konstrukci podmínky DynSQL případná omezení podle přístupových práv obdobně jako je tomu u dokladových agend (viz Omezení versus Přístupová práva)!!! Tzn., že pokud je v daném číselníku např. nadefinována číselníková uživatelsky definovatelná položka s odkazem do číselníku chráněných objektů s nastavením Používat pro omezení výběrů dat, tak se uživateli po otevření číselníku, který podporuje skupinování, načtou JEN ty záznamy, které vyhovují jeho přístupovým právům k danému chráněnému objektu. Toto zohledňování práv lze ovlivnit zadáním parametrů do definice dané uživatelsky definovatelné položky. (Viz popis číselníkových definovatelných položek a příklady v popisu uvedené).
Každá definice skupiny záznamů může být určena jen pro uživatele, který ji vytvořil nebo i pro ostatní uživatele (tzv. "globální definice"). Viz položka Globální v definici skupiny. Běžný uživatel se tudíž definicemi nemusí zabývat a může využívat definice, které mu připraví někdo jiný – např. správce systému. Změny, které jsou provedeny (a uloženy) v globálních definicích někým jiným, např. správcem, se automaticky promítnou všem, kteří hotové definice skupin záznamů používají a to bez nutnosti jejich vlastního přičinění. Kdo smí globální definice vytvářet a měnit, lze určit přístupovými právy - právem Modifikovat globální uživatelské skupiny číselníků.
Jak číselník skupin záznamů po svém vyvolání, tak nabídka skupin k výběru (viz možnosti přepínání mezi skupinami) je apriori omezena jen za ty skupiny, které může daný uživatel použít. (Tj. jsou buď globální nebo jsou lokální, ale jím definované). Pokud existuje definic skupin záznamů víc, ale uživatel mezi nimi nechce přepínat (např. proto, že každá definice je určena jiné skupině uživatelů), pak si může tu "svou", kterou chce přednostně používat, nastavit jako "výchozí". Tato se pak vždy přednostně automaticky použije při prvním otevření dané agendy daným uživatelem. Příznak "výchozí" se pamatuje na agendu a uživatele, tedy každý uživatel může mít jako výchozí jinou skupinu. Kromě toho může být jedna z globálních definic nastavena jako "výchozí globálně" (může ji nastavit uživatel s právem Modifikovat globální uživatelské skupiny číselníků). Tato se pak přednostně automaticky použije při prvním otevření dané agendy daným uživatelem, pokud tento nemá nastavenu "svou výchozí". Nastavení výchozích jsou uloženy v repositoři a zálohují se. Kromě toho se pamatuje naposledy použitá skupina daným uživatelem v dané agendě.
Postup platný pro výběr skupiny:
- Při prvním vstupu uživatele do agendy po spuštění systému IS FLORES se předvyplňuje skupina v tomto pořadí:
- Pokud existuje definice nastavená jako "výchozí" daným uživatelem, pak se použije.
- Pokud pro danou agendu není žádná výchozí skupina nebo pokud taková skupina není aktuálně k výběru k dispozici (tj. je aktuálně nadefinována jen jako lokální pro jiného uživatele či byla smazána), použije se skupina nastavená jako "globálně výchozí".
- Pokud žádná dostupná definice není "výchozí" ani "globálně výchozí", použije se skupina zapamatovaná jako naposledy použitá.
- Pokud není žádná zapamatovaná nebo není aktuálně dostupná, použije se volba Všechny záznamy.
- Při dalším vstupu (tj. dalším otevření téže agendy v rámci běžícího systému IS FLORES)
- Použije se skupina zapamatovaná jako naposledy použitá.
- Pokud tato není aktuálně k dispozici (viz výše), použije se volba Všechny záznamy.
Uživatel si však může vybrat jinou skupinu ručně nebo si může otevřít editor skupin záznamů a zde si nadefinovat novou skupinu a tu si vybrat. Takto ručně vybraná skupina se bude používat, dokud nebude systém IS FLORES zavřen. Po jeho znovuotevření se opět přednostně použije skupina nastavená jako výchozí.
Vybraná skupina se neuplatní, pokud obsahuje chybu. Tj. např. obsahuje omezení za výraz, ale výraz je chybně zapsaný a tudíž nelze sestavit správně DynSQL dotaz. V takovém případě se agenda otevře bez uplatnění skupin záznamů. Z technických důvodů ale tuto událost nelze uživateli oznámit, nicméně provede se o ní zápis do logu. Log se jmenuje RollOperation. Uživatel by poté měl dotyčnou definici skupiny opravit!
Dále viz popis položek a funkcí v číselníku skupin záznamů.
Z výše uvedeného výkladu plyne, že v provozech s méně zkušenými uživateli lze, aby definici skupin záznamů vytvořil, udržoval a spravoval nějaký nadřízený znalejší správce a koncoví uživatelé tyto definice pouze používali a pokud správce definici upraví, změna se jim automaticky promítne.
Správce nadefinuje v agendě adresáře jednu skupinu záznamů k zobrazení pro obchodníky a druhou pro nákupčí. Uživatelům na jejich počítačích nastaví použití těchto definic jako výchozí. Když později přidá podmínku do uložené definice pro obchodníky, obchodníkům se už bez jakéhokoliv zásahu na jejich počítačích tato podmínka použije.
Použití skupin a označení výchozí a výchozí globálně lze rozdělit zhruba na tři následující případy:
- Případ 1 - pokud firma nemá ambice nastavovat skupiny, uživatelům se pamatuje naposledy použitá.
- Případ 2 - pokud firma chce řídit nastavení skupin, pak nastaví vybranou globální skupinu jako "výchozí globálně" a běžní uživatelé bez ambicí si ji změnit ji prostě používají a pokud si ji změní, je to pouze dočasné.
- Případ 3 - pokud firma nastaví globální skupinu a některý uživatel to chce jinak, může si nastavit svou vlastní výchozí skupinu.
Mějme firmu s jednou pobočkou, kde pobočka pracuje se zcela jiným sortimentem než centrála a nijak se nepřekrývají. Pak může mít centrála i pobočka nadefinovanou skupinu karet, se kterou bude pracovat. Pak firma nebude definovat žádnou skupinu jako výchozí globálně a každý uživatel si přepne karty na "svoji" skupinu a ta se mu bude pamatovat, příp. si ji nastaví pro sebe jako výchozí. Proti tomu v případě centrální firmy bez poboček lze s výhodou nadefinovat např. skupinu aktivních karet (bez karet naimportovaných z dodavatelských ceníků) a všem uživatelům nastavením výchozí globálně tuto "vnutit", přičemž pokud uživatel pracuje výjimečně i s jinými kartami (jelikož má na starost např. ceníky), nastaví si pro sebe jinou skupinu jako výchozí.
Další vlastnosti skupinování:
- V případě, že v nějaké agendě se předvyplňuje záznam z číselníku, který podporuje skupinování (např. Firma pro předvyplnění nastavená ve Firemním nastavení), nebo dochází k jeho převzetí z jiného dokladu (např. firma přebíraná ze zdrojového dokladu do cílového apod.) se takový číselníkový záznam bez problémů převezme a použije, a vystavovaný doklad je možné v pořádku uložit, bez nutnosti mít tento záznam zařazený v aktuálně použité skupině.
Skupinování za položky s historií je k dispozici pouze v omezené míře, viz též Omezování za položky s historií.
Volba skupiny se vztahuje jen na záznamy evidované přímo ve vyvolané agendě, tj. platí jen pro hlavní seznam dané agendy.
K tvorbě definic uživatelských skupin slouží Editor skupin záznamů realizovaný jako běžný číselník Skupin záznamů. Pomocí něj lze definice přidávat, upravovat, mazat. K dispozici jsou různé možnosti, jak vyvolat editor nebo jak přepínat mezi již existujícími definicemi skupin:
Vlastní skupinu záznamů nadefinujete:
- volbou v menu: Nastavení->Skupiny záznamů->Editor skupin záznamů - platí jen pro hlavní seznam dané agendy. Editor skupin záznamů se liší od jiných editorů (např. pro definice sloupců, panely def. údajů apod.). Tato volba v menu vyvolá číselník Skupin záznamů defaultně zafiltrovaný za skupiny záznamů nadefinované pro aktuální agendu. Ve vyvolaném číselníku nadefinujete skupiny dle vašich požadavků standardním způsobem, tj. zadáním nových záznamů do daného číselníku stejně jako u jakéhokoliv jiného číselníku, každou skupinu pod zadaným kódem a názvem. Nové skupiny přibudou pod svým zadaným kódem jako volba v příslušné větvi menu:
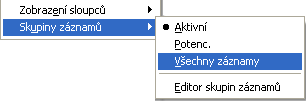
Příklad části menu Nastavení s nabízenými dvěma skupinami záznamů pod názvem Aktivní a Potenciální. (Zde zobrazený název odpovídá kódu skupiny v číselníku Skupiny záznamů.) Volba Všechny záznamy slouží pro načtení všech, viz Ovládání dále. Skupina Aktivní je aktuálně zvolena (což indikuje puntík před názvem).
Přihlášenému uživateli se nabízí k použití pouze skupiny záznamů, které si nadefinoval sám nebo ty, které jsou nadefinované jako Globální.
- volbou Editor skupin záznamů z lokálního menu vyvolaného pravým tlačítkem myši nad tlačítkem Skupina v informačním panelu - možno jen, je-li nadefinována alespoň jedna skupina, jinak se zde tlačítko nezobrazuje. Ve vyvolaném číselníku nadefinujete skupiny jako v prvním popsaném případě, viz výše.
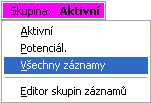
Příklad lokálního menu s nabízenými dvěma skupinami záznamů pod názvem Aktivní a Potenciální. Skupina Aktivní je aktuálně zvolena (což je indikováno vzhledem tlačítka Skupina).
Jak bylo zmíněno výše, nabídka skupin je apriori omezena jen za ty definice, které může daný uživatel použít. (Tj. jsou buď globální nebo jsou lokální, ale jím definované).
- vyvoláním Editoru skupin záznamů kliknutím levým tlačítkem myši na tlačítko Skupina v informačním panelu - možno jen, je-li nadefinována alespoň jedna skupina, jinak se zde tlačítko nezobrazuje. Ve vyvolaném číselníku nadefinujete skupiny jako v prvním popsaném případě, viz výše.
Použití skupiny záznamů "zapnete":
- volbou v menu: Nastavení->Skupiny záznamů-> volbou skupiny
- volbou z lokálního menu vyvolaného pravým tlačítkem myši nad tlačítkem Skupina v informačním panelu -> volbou skupiny
- vyvoláním Editoru skupin záznamů - číselníku Skupiny záznamů (možnosti viz výše) a poté použitím funkce Použít pro vybranou skupinu
Zvolená skupina platí jen pro hlavní seznam dané agendy. Objasníme na příkladu:
Agenda
Možnosti přepínání mezi skupinami:
Změnu skupiny záznamů provedete:
- volbou v menu: Nastavení->Skupiny záznamů-> výběrem jiné skupiny
- volbou z lokálního menu vyvolaného pravým tlačítkem myši nad tlačítkem Skupina v informačním panelu -> výběrem jiné skupiny
- vyvoláním Editoru skupin záznamů - číselníku Skupiny záznamů (možnosti viz výše) a poté použitím funkce Použít pro vybranou skupinu
Použití skupiny záznamů vypnete:
- volbou v menu: Nastavení->Skupiny záznamů-> volbou Všechny záznamy
- volbou z lokálního menu vyvolaného pravým tlačítkem myši nad tlačítkem Skupina v informačním panelu -> volbou Všechny záznamy
Po výběru skupiny resp. po změně skupiny (po výběru jiné) se automaticky provede načtení odpovídající části číselníku z databáze do paměti, tj. záznamů, které odpovídají podmínkám dané skupiny. (Tím dojde i k
Načtené záznamy z databáze nemusí být nutně všechny viditelné, v závislosti na případném filtrování příp. jiném omezení číselníků. Viz Skupiny záznamů versus filtrování či jiné omezení číselníků.
Pokud v číselníku existuje nějaká skupina záznamů, je informace o použití skupin zobrazena v informačním panelu pomocí tlačítka Skupina. Informace o skupině se zobrazuje následovně:
- "Skupina: Všechny záznamy":
 - Pokud existuje nějaká skupina, ale aktuálně není žádná vybrána.
- Pokud existuje nějaká skupina, ale aktuálně není žádná vybrána. - "Skupina: {Kód skupiny}" s odpovídajícím barevným podkladem (dle svolené barvy v definici skupiny).
Jedná se o funkční tlačítko ovládané myší. Levé tlačítko myši vyvolává Editor skupin záznamů (číselník skupin záznamů), pravé tlačítko myši pak lokální menu s nabídkou všech podvoleb pro práci se skupinami, vč. volby pro zrušení skupinování (zobrazení všech záznamů) a voleb pro přepínání mezi existujícími skupinami. Jedná se o jednu z možností přepínání mezi skupinami resp. možností, jak vyvolat editor skupin záznamů. Viz Ovládání výše.